单台windows搭建mysql主从机备份
1.在一台window上搭建两个MySQL实例
1.1.下载 MySQL 5.6
下载地址:http://download.csdn.net/download/zzu_wang/8708049
注意,一定要下载 5.6 版本,5.7版本会出现各种各样奇怪的问题。
1.2.建立对应目录
在你喜欢的位置(我的是D:\WorkSpace\mysql\)建立两个文件夹,分别叫 mysql5601 和 mysql5602。将刚才下载到的 zip 文件分别复制到这两个文件夹中解压。
解压完成之后应该是这个样子的:
1.3.修改响应配置文件
分别打开 mysql5601 和 mysql5602 ,修改 my-default.ini 文件
打开 my-default.ini 文件,修改下图中标记的位置
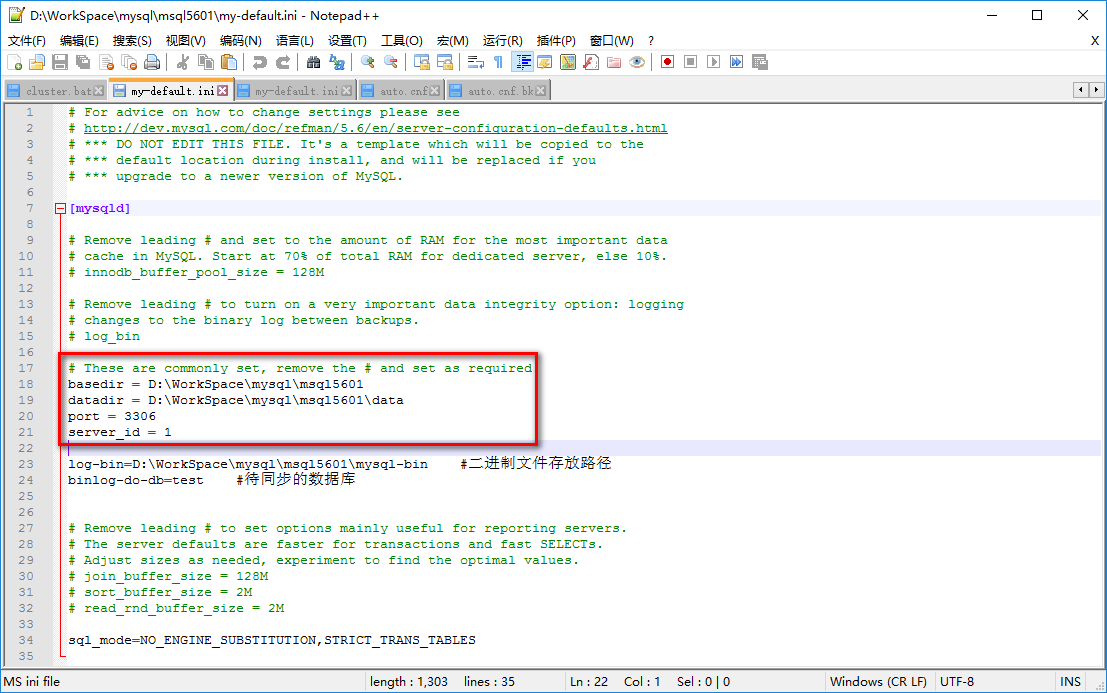
basedir 为 mysql 的解压目录,datadir 为 basedir\data,两个实例的 port 分别设置为 3306 和 3307,server_id 分别设置为 1 和 2。
mysql5601:
|
|
mysql5602:
|
|
注意,只修改刚才提到的地方就好,其他地方暂时先不用管,后面会有提到。
1.4.启动 MySQL 服务
在 windows 搜索框中搜索 cmd,得到结果如下图所示:
按下 Ctrl + Shift + Enter,以管理员身份进入 cmd,进入之后,如下图所示:
进入到 D:\WorkSpace\mysql\msql5601\bin 目录下,输入:
|
|
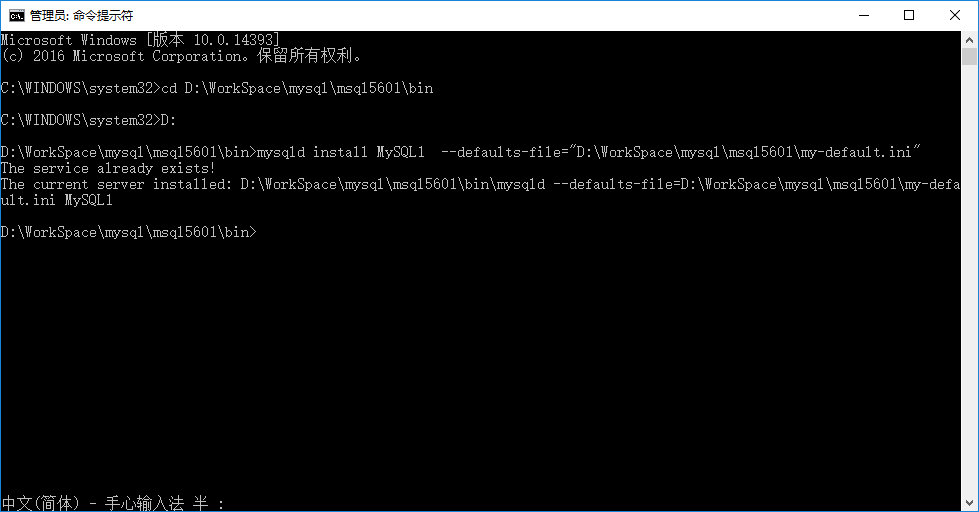
因为我已经安装过了,所以会显示 The service already exists! ,第一次安装应该显示 Service successfully installed.
【MySQL1】是服务的名称,安装成功后,在 windows 搜索里输入【服务】,可以在服务中找到它。
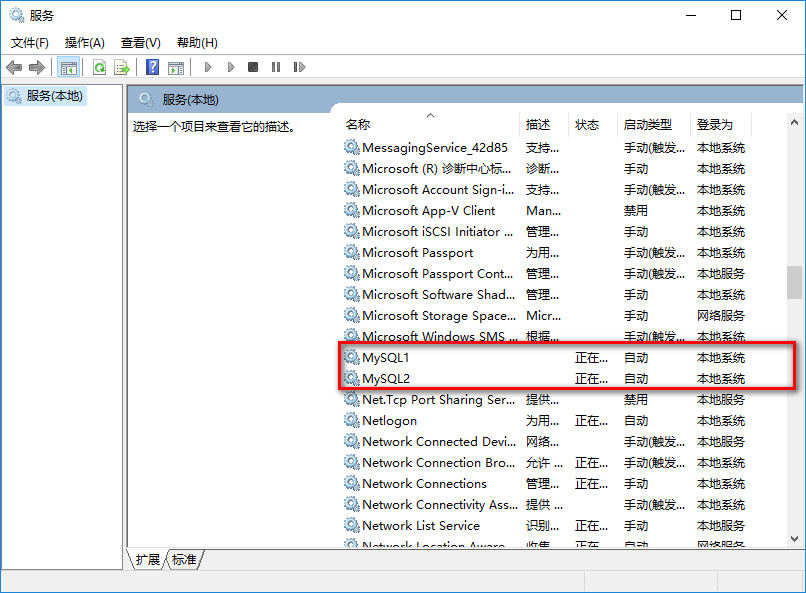
安装成功后,输入 net start MySQL1,启动这个服务:
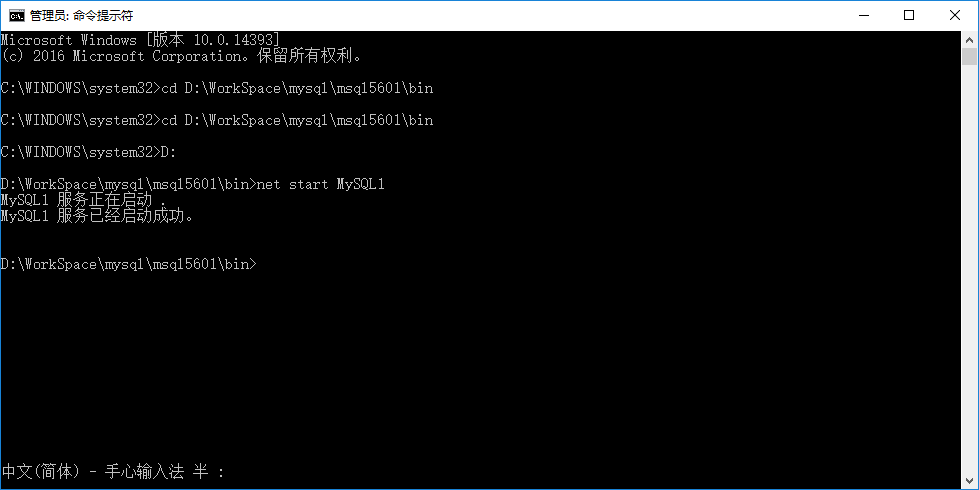
然后用同样的方法启动另一个服务,这回叫MySQL2:
进入到 D:\WorkSpace\mysql\msql5602\bin 目录下,输入:
|
|
安装成功后,输入 net start MySQL2,启动这个服务,得到结果如下图所示:
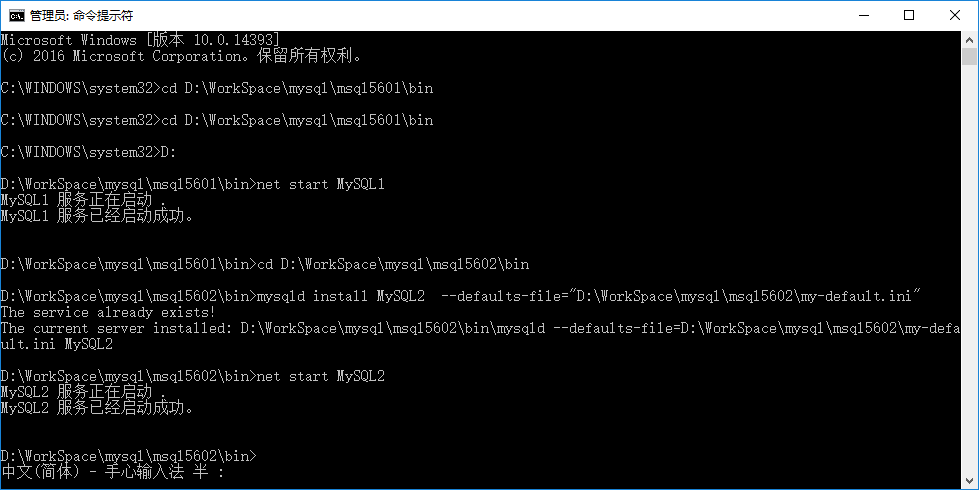
两个服务都跑起来之后,我们就可以进入下一步:实现主从备份了。
2.搭建主从备份
2.1.在两个 MySQL 实例创建数据库
我们以 mysql5601 中的实例作为主库,以 mysql5602 中的实例作为从库。
在这两个数据库中各自创建一个叫做 test 的库作为用来同步的库。具体操作如下:
进入 D:\WorkSpace\mysql\msql5602\bin 目录下,输入 mysql -uroot -proot -P3306
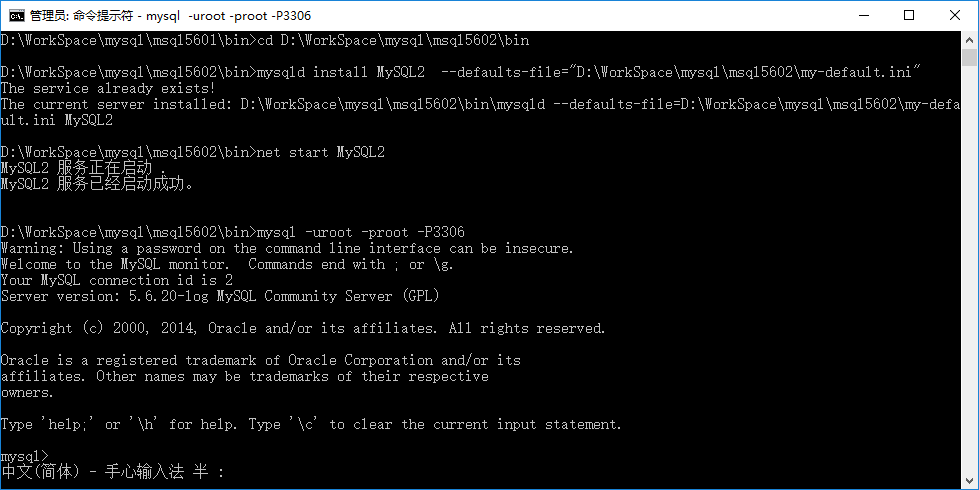
在这个命令中,前一个小写的 p 是密码(password)的 p,后一个大写的 P 是端口(Port)的 P。
然后输入:create database test;
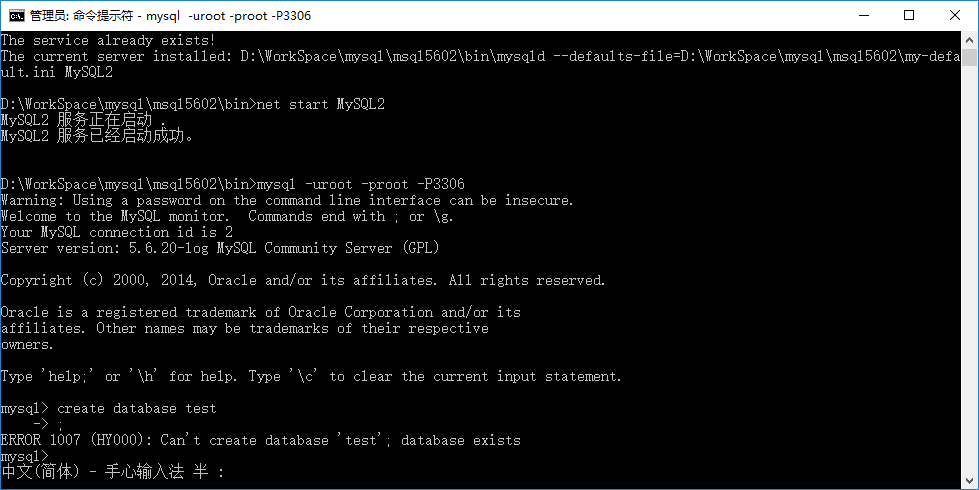
我的因为已经建立过了,所以会报出 database exists。
输入:show databases;
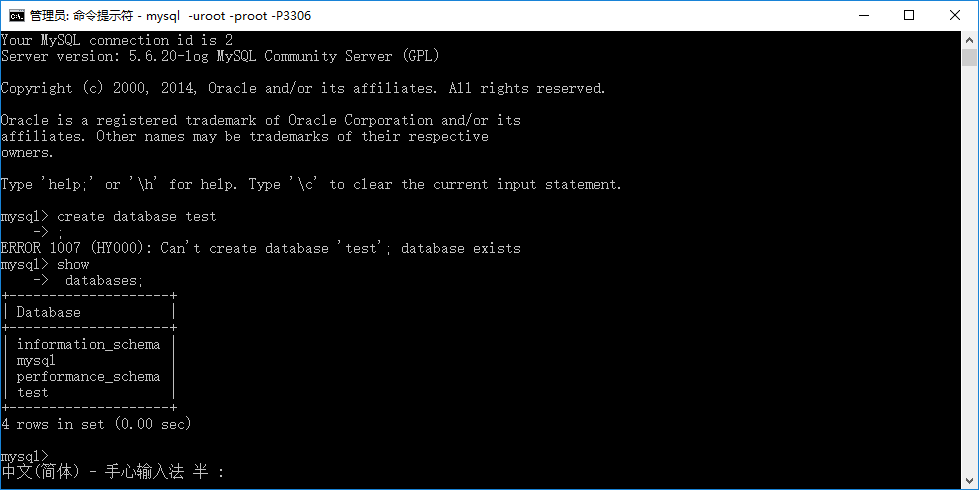
显示现有的 database,我们可以看到,test已经在里面了。
接下来我们建立从机的数据库,打开一个cmd,进入 D:\WorkSpace\mysql\msql5602\bin 目录下,输入 mysql -uroot -proot -P3307
然后输入:create database test;
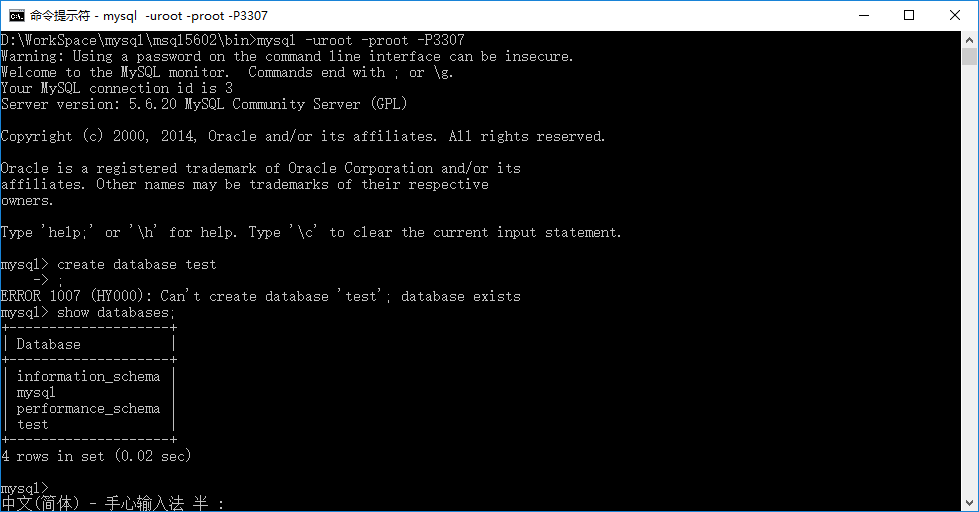
这样两个数据库就建立好了。
2.2.修改主库配置文件
打开 mysql5601,修改 my-default.ini 文件,在其中添加如下内容:
|
|
添加完后,我们的 my-default.ini 文件就会像下面这样:
|
|
Windows 搜索【服务】,重启 MySQL1 服务。
重启之后,你会看到 D:\WorkSpace\mysql\msql5601 目录下多出了两个文件(因为我重启过三遍所以多出来四个):
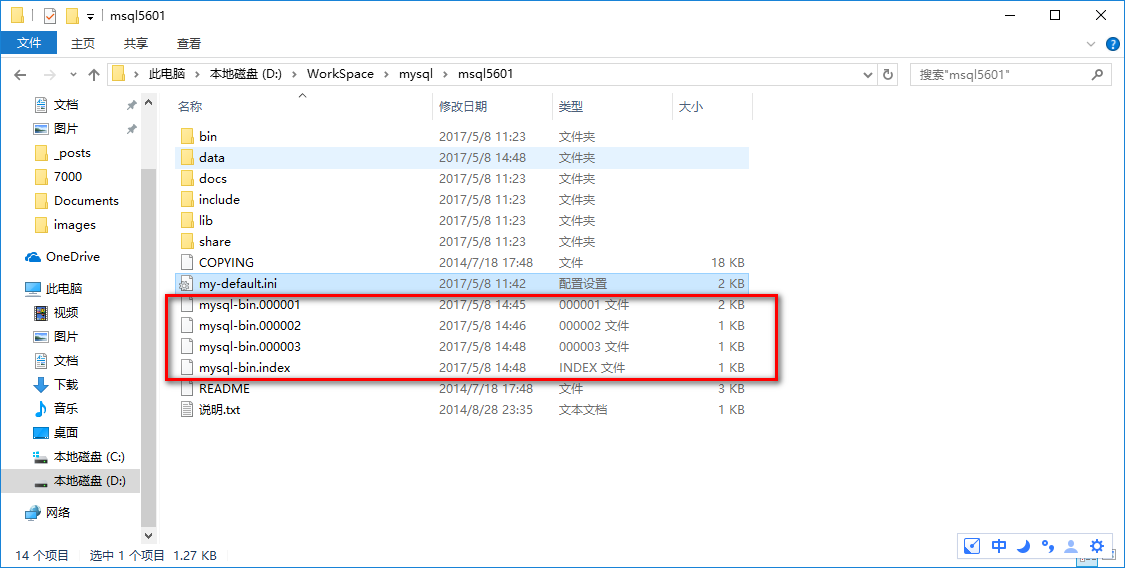
2.3.给要连接的从服务器设置权限
打开一个cmd,进入 D:\WorkSpace\mysql\msql5602\bin 目录下,输入 mysql -uroot -proot -P3306
进入 mysql 命令行模式,输入
|
|
给主机10.0.76.192添加权限,用户名:slave,密码:root;
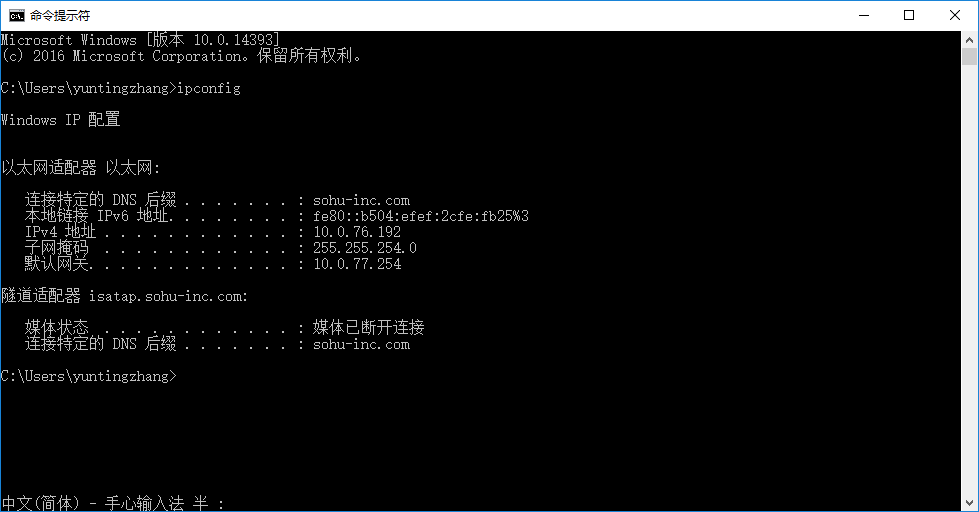
注意,10.0.76.192是我的 ip 地址,这个地址需要改成你自己的 ip 地址(如果不是一台机器则要改成从机的 ip 地址)。查询 ip 地址的方法很简单,打开 cmd,输入 ipconfig 即可。
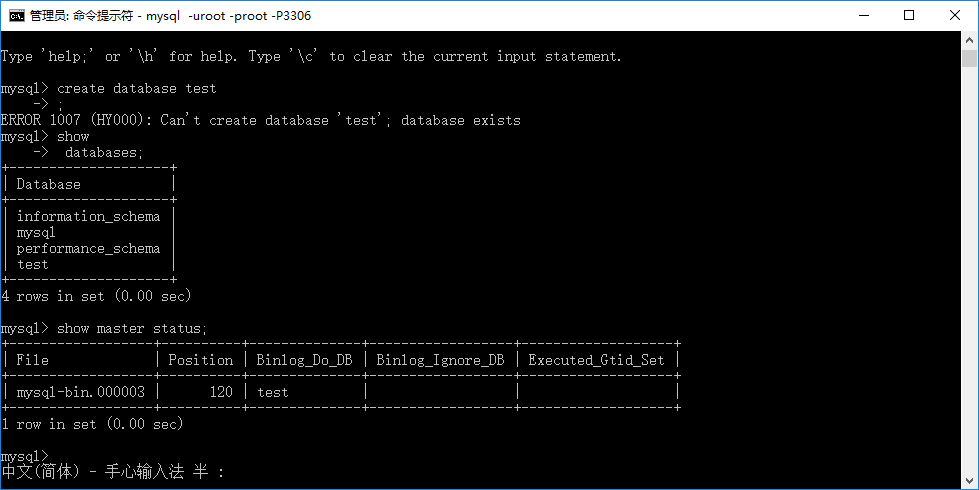
2.4.输入命令 show master status;
找到 File 和 Position 的值记录下来,这些值后面会用到。
2.5.修改从库配置文件
打开mysql5602,修改my-default.ini文件:
|
|
修改后的 my-default.ini 文件如下所示:
|
|
重启 MySQL2 服务。
2.6.修改从库对主库的连接参数
打开一个cmd,进入 D:\WorkSpace\mysql\msql5602\bin 目录下,输入 mysql -uroot -proot -P3307
进入 mysql 命令行模式,输入:
|
|
注意:这里输入的 mysql-bin.000003 和 120 请替换为步骤2.4中查询出来的值,master_host 替换为你自己的 ip。
2.7.启动 salve 线程
输入:start slave;
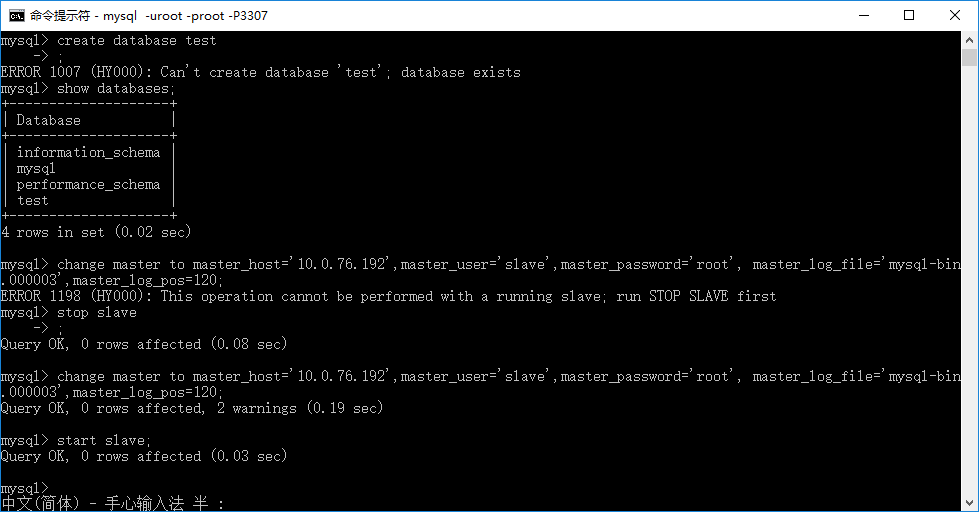
然后输入:show slave status\G (没有分号)
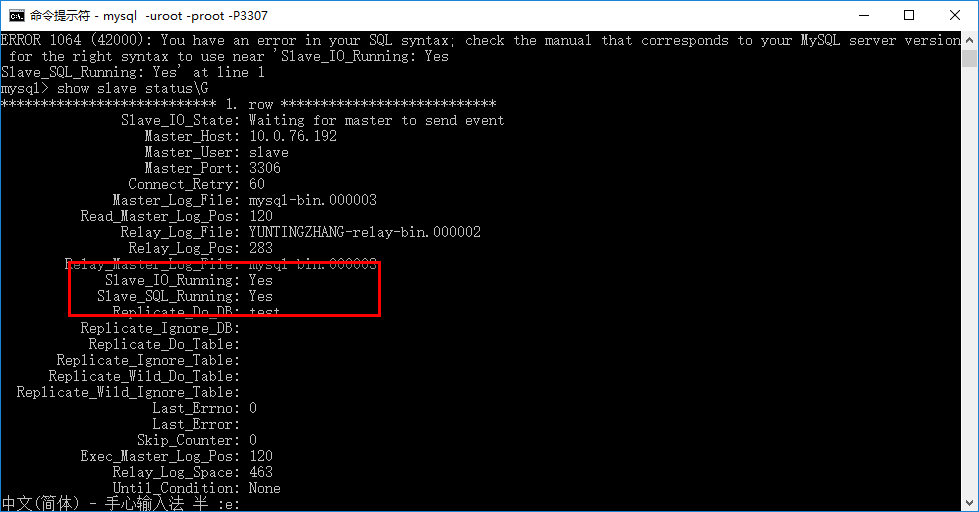
看是否有以下两行:
|
|
这两个指标非常重要,任意一行为No都不能正常运行。我就曾经遇到了下面的这种问题。
|
|
解决方法很简单,重启以下 slave 的服务就可以了。
2.8.测试同步
打开两个 cmd ,进入 D:\WorkSpace\mysql\msql5602\bin 目录下,分别输入:
|
|
在主机上输入:use test;
转到 test 数据库,然后输入:create table table1;
新建一个名为 table1 的表。然后输入:show tables;
得到结果如下图所示:
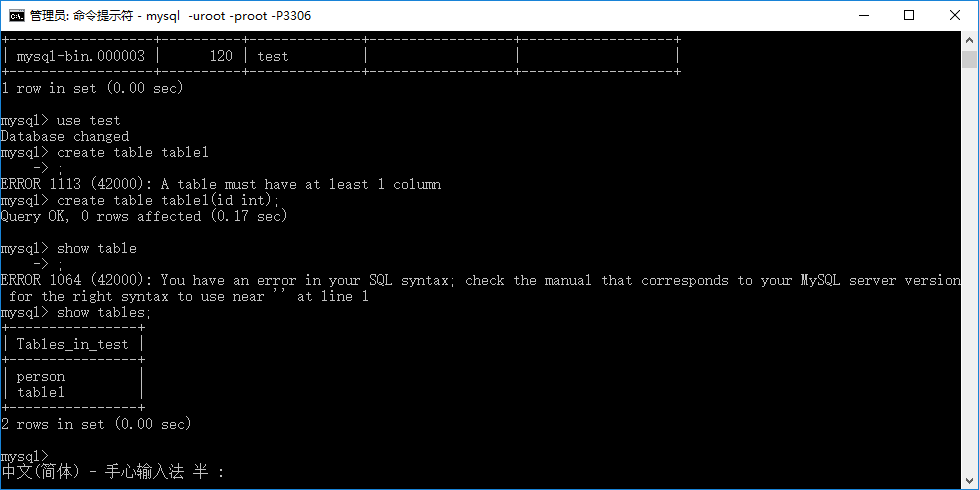
上面的操作只是在主机上的 test 数据库中建立了一张名为 table1 的表。
接下来我们进入从机的 cmd,输入:use test;
然后输入:show tables;
得到结果如下图所示:
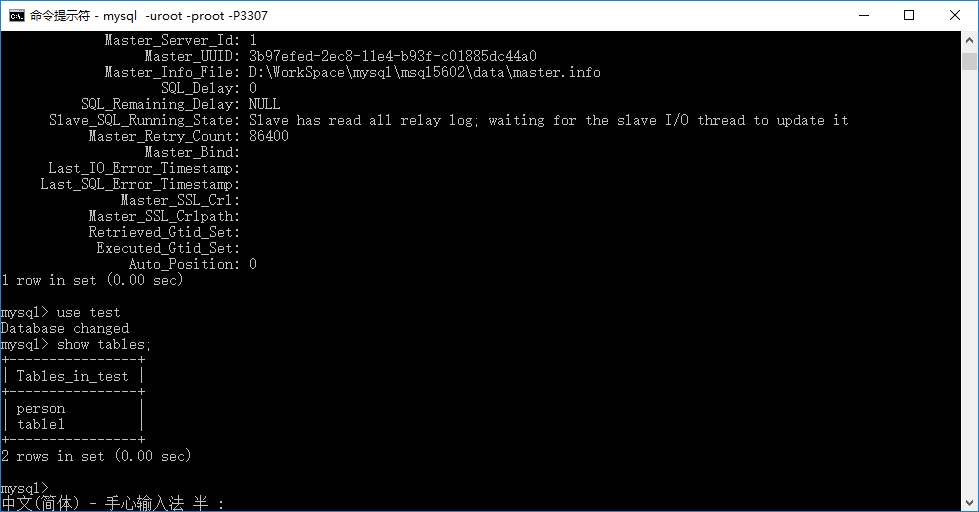
可以看到,两个数据库的数据已经开始自动同步了。
3.参考链接
windows下mysql主从同步
http://www.cnblogs.com/xiaochangwei/p/4824355.html
mysql (master/slave)复制原理及配置
http://blog.csdn.net/mer1234567/article/details/7405775
window下一台PC机器上安装多个mysql的方法
http://blog.csdn.net/zfqzpp/article/details/13630905
mysql 数据同步 出现Slave_IO_Running:No问题的解决方法小结
http://www.jb51.net/article/27220.htm
slave have equal MySQL Server UUIDs原因及解决
http://www.linuxidc.com/Linux/2015-02/113564.htm
4.操作系统:windows10
单台windows搭建zookeeper和kafka集群
我们的目标是在一台机器上部署三个zookeeper的server,并在此基础上部署三个zookeeper的server。
1.zookeeper的部署
zookeeper的部署采用伪集群模式,即在一台电脑上部署多个server。
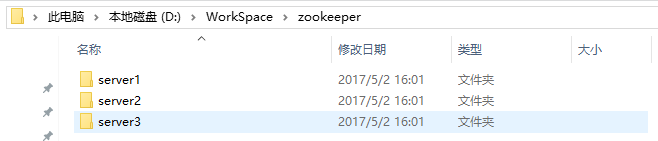
1.1.建立文件夹,存放项目
在你喜欢的位置(我的目录为D:\WorkSpace)建立一个名为zookeeper的文件夹,并在该文件夹下建立三个目录,分别名为server1,server2和server3。完成之后如下图所示:
1.2.下载zookeeper
下载地址:http://apache.fayea.com/zookeeper/。或者直接去zookeeper官网自己找对应的版本也是一样的。
1.3.解压文件并创建一些目录
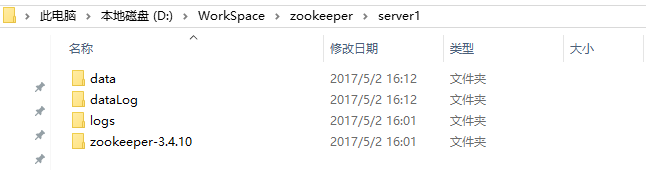
将下载好的压缩包解压到server1目录下,并在server1目录下建三个文件夹,分别名为data,dataLog和logs。完成之后应该是这样的。
注意:压缩包解压的时候直接选【解压到当前文件夹】即可。所以上图中的zookeeper-3.4.10文件夹打开之后应该是这样的:
1.4.在server1/data目录下,创建一个叫做myid的文件。
注意,这个文件不需要任何扩展名,所以显示的形式如下图所示:

如果你看到的myid文件不是这样的,说明你的扩展名没有去除。在windows系统下,文件扩展名默认是被隐藏的。在【查看】选项卡里勾选【文件扩展名】,你就能看到被隐藏的扩展名了。

1.5.打开myid文件,在里面添加对应的id
因为我们目前配置的是server1,所以添加id为1,然后关闭即可。

这里打开myid文件使用的编辑器是notepad++,如果没有安装的话,可以下载一个安装一下。下载地址:https://notepad-plus-plus.org/。
1.6.修改配置文件
在server1/zookeeper-3.4.10/conf目录下,新建zoo.cfg文件,加入内容如下:
|
|
注意,dataDir和dataLogDir中的D:/WorkSpace目录需要改成你自己的目录。
这里对zoo.cfg中的内容进行简要地说明:
tickTime为客户端与服务器之间或服务器互相之间的心跳间隔,以ms为单位。
initLimit为leader与follower进行初始连接时最多能够容忍的心跳数。
syncLimit为follower与leader请求和应答之间最多能容忍的心跳数。
dataDir为数据文件目录。
dataLogDir为日志文件目录。
clientPort为客户端连接服务器的端口,zookeeper监听此接口接收客户端访问请求。
最后三行为集群中每个服务器的ip和端口号。前一个端口为leader和follower通信端口,后一个端口为选举新leader时所用的端口。一般来说,在多台电脑的情况下,每台服务器上的端口配置是一样的。不过我们现在使用同一台电脑配置三个server,为了避免冲突,只能把它们改成不一样。
1.7.复制server1中的内容到server2和server3中,并修改相应配置
将server1中的内容分别复制到server2和server3中,并修改/data/myid文件和/zookeeper-3.4.10/conf/zoo.cfg文件。
myid文件只需要将其中的内容改成服务器的序号即可。
zoo.cfg文件需要修改dataDir,dataLogDir和clientPort。修改后的三个文件如下:
server1:
|
|
server2:
|
|
server3:
|
|
1.8.启动服务器
分别进入三个server的/zookeeper-3.4.10/bin目录下,运行:zkServer start 。结果如下图所示:
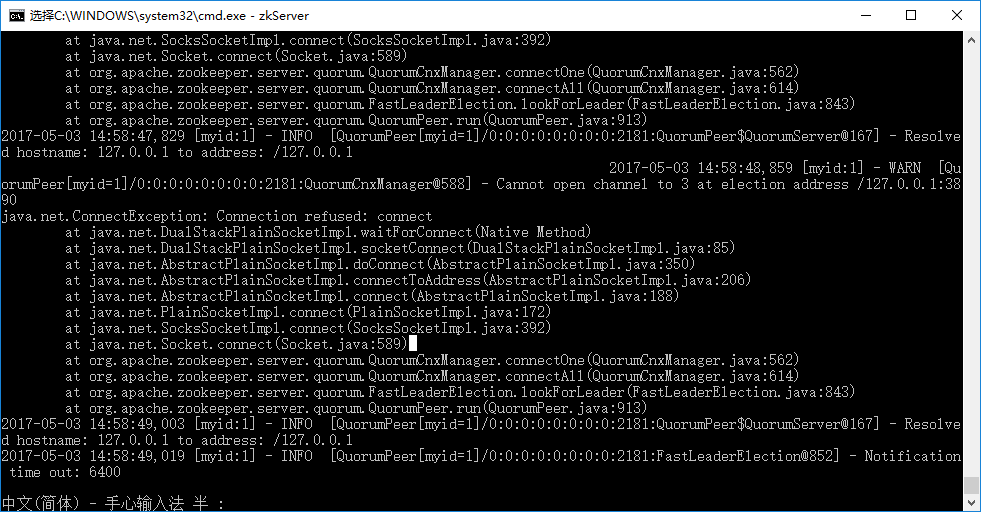
第一个server启动的时候会报错,这是由于它想要和其他两个server进行通信,而另外两个server还没有搭建起来。不用理会这个错误,继续打开新的cmd窗口,启动其他server就好。注意,原来的窗口不要关!所有server都启动了之后,显示如下:
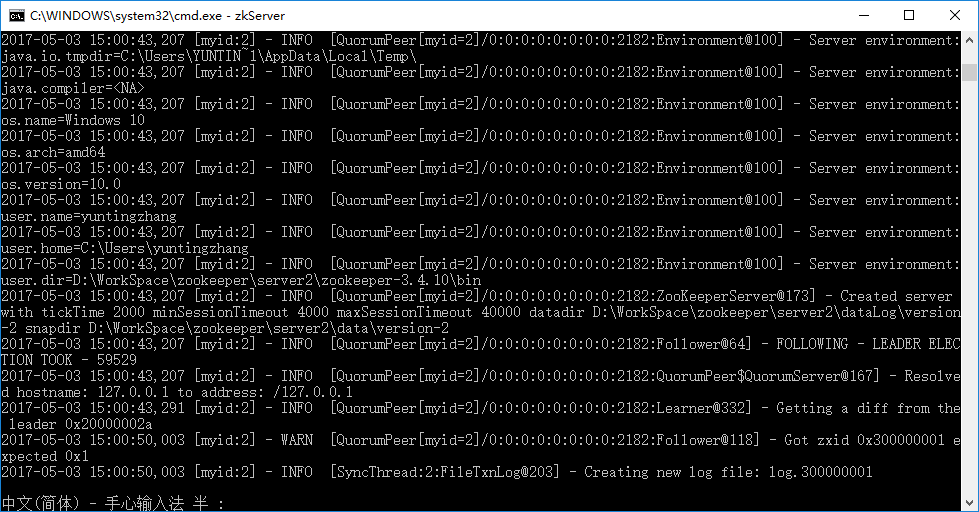
如果报Invalid arguments, exiting abnormally 的异常的话,只需要在 zkServer start 命令中去掉start,即输入zkServer即可。
1.9.连接客户端
进入任意一个zookeeper-3.4.10目录下,用以下命令启动客户端:zkCli –server 127.0.0.1:2181
,显示如下结果:
输入help,显示可以执行的指令。
做到这一步,zookeeper集群的搭建就完成了。接下来我们要在此基础上搭建kafka的集群。
2.kafka的部署
kafka在设计的时候就依赖于zookeeper,对于kafka而言,zookeeper相当于它的文件系统。每个节点的信息都保存在zookeeper对应的路径下。
(1)Broker注册:Broker在zookeeper中保存为一个临时节点,节点的路径是/brokers/ids/[brokerid],每个节点会保存对应broker的IP以及端口等信息。
(2)Topic注册:在kafka中,一个topic会被分成多个区并被分到多个broker上,分区的信息以及broker的分布情况都保存在zookeeper中,根节点路径为/brokers/topics,每个topic都会在topics下建立独立的子节点,每个topic节点下都会包含分区以及broker的对应信息。
(3)消费者与分区的对应关系:对于每个消费者分组,kafka都会为其分配一个全局唯一的Group ID,分组内的所有消费者会共享该ID,kafka还会为每个消费者分配一个consumer ID,通常采用hostname:uuid的形式。在kafka的设计中规定,对于topic的每个分区,最多只能被一个消费者进行消费,也就是消费者与分区的关系是一对多的关系。消费者与分区的关系被存储在zookeeper中节点的路径为 /consumers/[group_id]/owners/[topic]/[broker_id-partition_id],该节点的内容就是消费者的Consumer ID。
(4)消费者负载均衡:消费者服务启动时,会创建一个属于消费者节点的临时节点,节点的路径为 /consumers/[group_id]/ids/[consumer_id],该节点的内容是该消费者订阅的Topic信息。每个消费者会对/consumers/[group_id]/ids节点注册Watcher监听器,一旦消费者的数量增加或减少就会触发消费者的负载均衡。消费者还会对/brokers/ids/[brokerid]节点进行监听,如果发现服务器的Broker服务器列表发生变化,也会进行消费者的负载均衡。
(5)消费者的offset:在kafka的消费者API分为两种(1)High Level API:由zookeeper维护消费者的offset (2) Low Level API:自己的代码实现对offset的维护。由于自己维护offset往往比较复杂,所以多数情况下都是使用High Level的API offset在zookeeper中的节点路径为/consumers/[group_id]/offsets/[topic]/[broker_id-part_id],该节点的值就是对应的offset。
看到这里,你就会明白kafka和zookeeper之间的关系了。我们现在就是要在已经配置好的zookeeper集群上配置kafka集群。
2.1.建立对应目录
还是找到你喜欢的那个目录(我的是D:\WorkSpace),建立一个叫做kafka的文件夹,里面建立三个子目录,分别叫做:kafka1,kafka2和kafka3。完成之后应该是这个样子:
2.2.下载kafka并解压到每个文件夹
kafka下载地址:
https://www.apache.org/dyn/closer.cgi?path=/kafka/0.10.2.1/kafka_2.12-0.10.2.1.tgz
下载之后是一个压缩包,还是直接解压到kafka1,kafka2和kafka3这三个文件夹就行。解压完后,在 kafka1,kafka2和kafka3目录下分别添加一个kafkaLog目录。最后的结果应该是这个样子的:
2.3.修改配置文件:
分别打开kafka1,kafka2和kafka3三个目录中的kafka_2.12-0.10.2.1/config路径下的consumer.properties文件,将里面的内容改成:
|
|
再打开这三个目录下的server.properties文件,按照下面内容进行修改:
kafka1:
|
|
kafka2:
|
|
kafka3:
|
|
2.4.启动kafka服务器
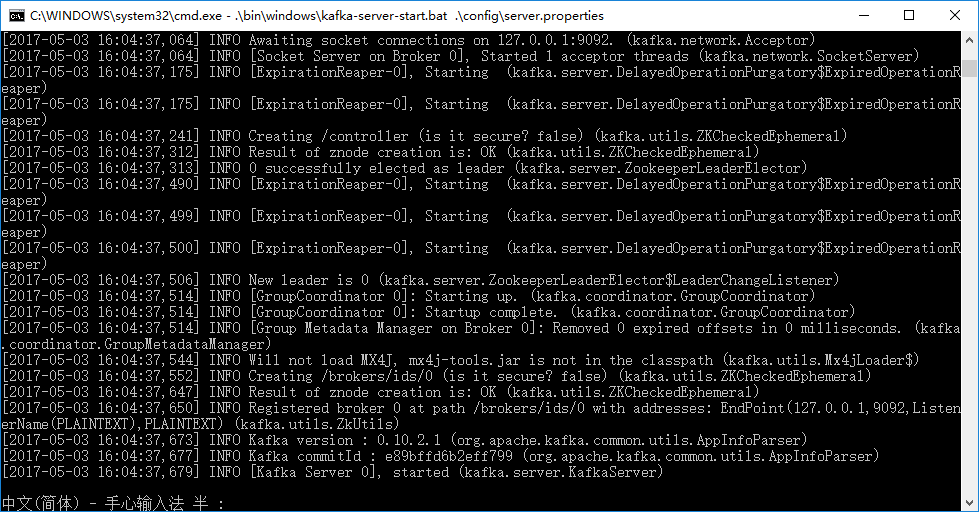
进入D:/WorkSpace/kafka/kafka1/目录下,输入
.\bin\windows\kafka-server-start.bat .\config\server.properties 命令,注意不要漏掉命令中的“.”。得到的结果如下图所示:
同样地,进入另外两个kafka2 和 kafka3目录下,把另外两个kafka服务器也启动起来。
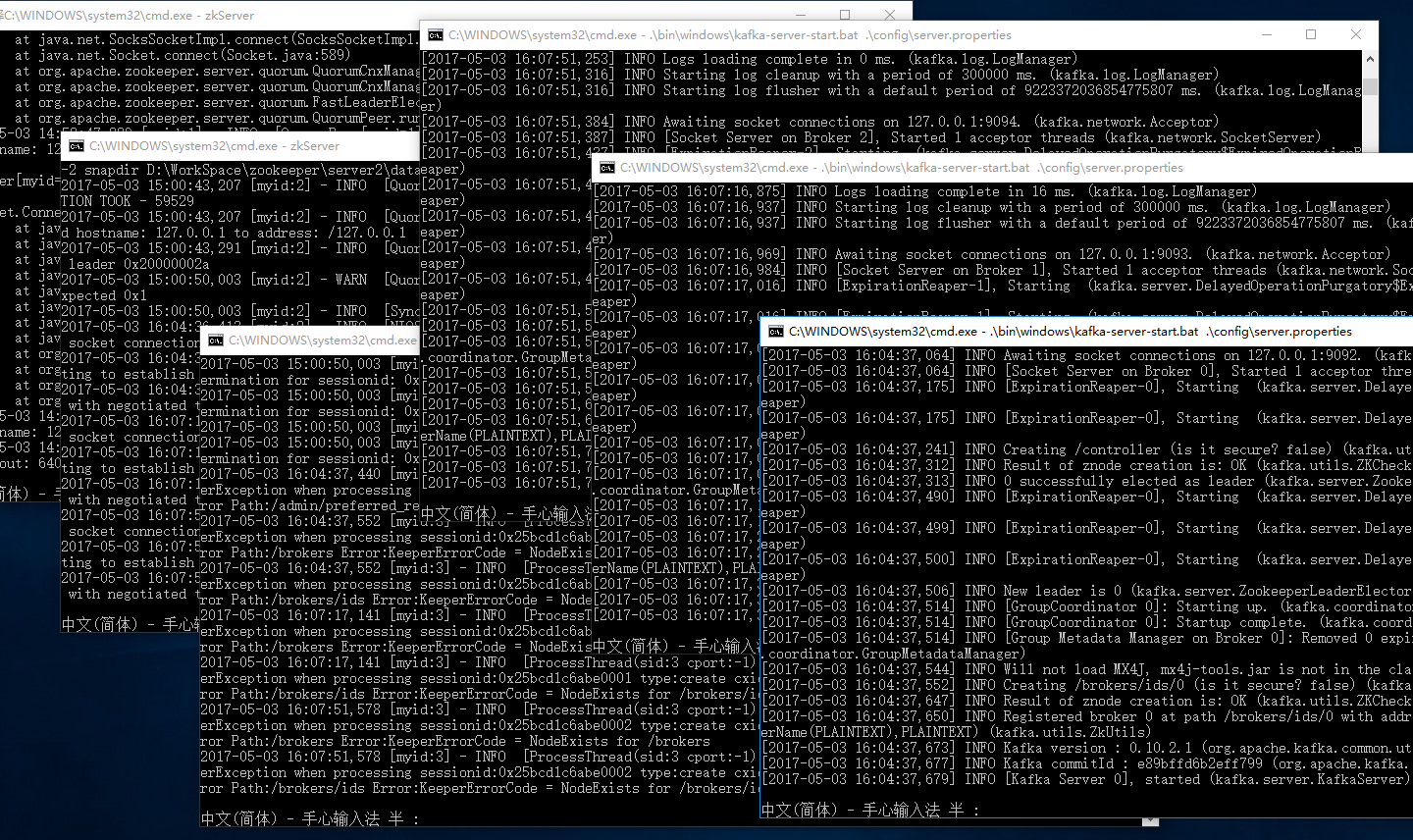
如果你最后得到的结果是这样的,那么恭喜你,zookeeper和kafka集群已经搭建完成了。
参考链接:
(1)在单机上实现ZooKeeper伪机群/伪集群部署 :
http://blog.csdn.net/poechant/article/details/6633923
(2)一台机器上安装zookeeper和kafka集群:
http://blog.csdn.net/u013244038/article/details/53938997
操作系统版本:windows 10
zookeeper版本:3.4.10
kafka版本:2.12-0.10.2.1
Eclipse搭建SpringBoot(一)HelloWorld
1.在Eclipse中安装STS插件
进入Eclipse,选择【help】→【Eclipse Marketplace 】
搜索→【STS】,找到【SpringToolSuite】并下载。

2.新建一个项目
【file】->【new】->【project】
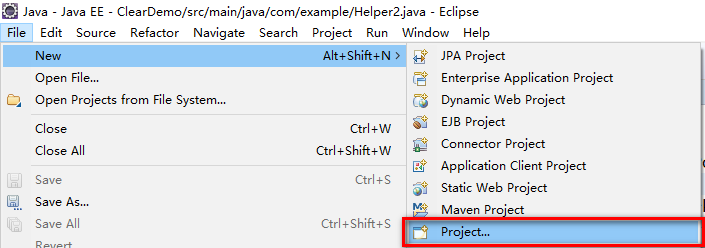
选择Spring Starter Project,然后【next】
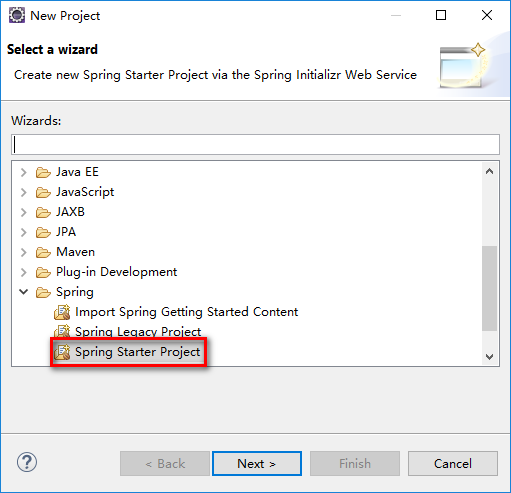
给你的项目取个名字,我的叫【bootDemo】,点击【next】
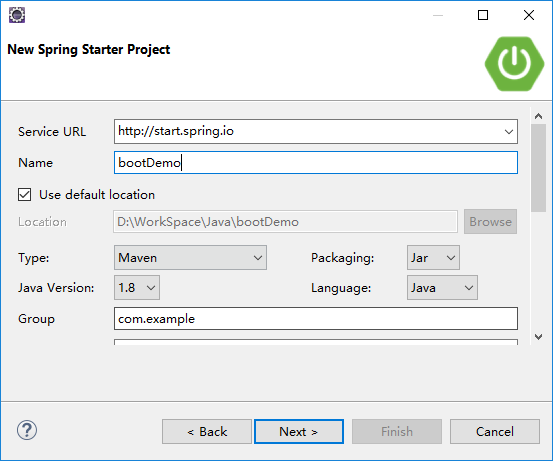
添加你所需要的依赖,由于我们现在只是演示,就只添加【core】中的【AOP】和【web】中的【web】。选好之后,点击【next】->【Finish】。
建好之后,你会得到这样一个工程:
3.运行程序
点击运行按钮,运行程序。运行方式选 Spring Boot App。
得到结果如下:
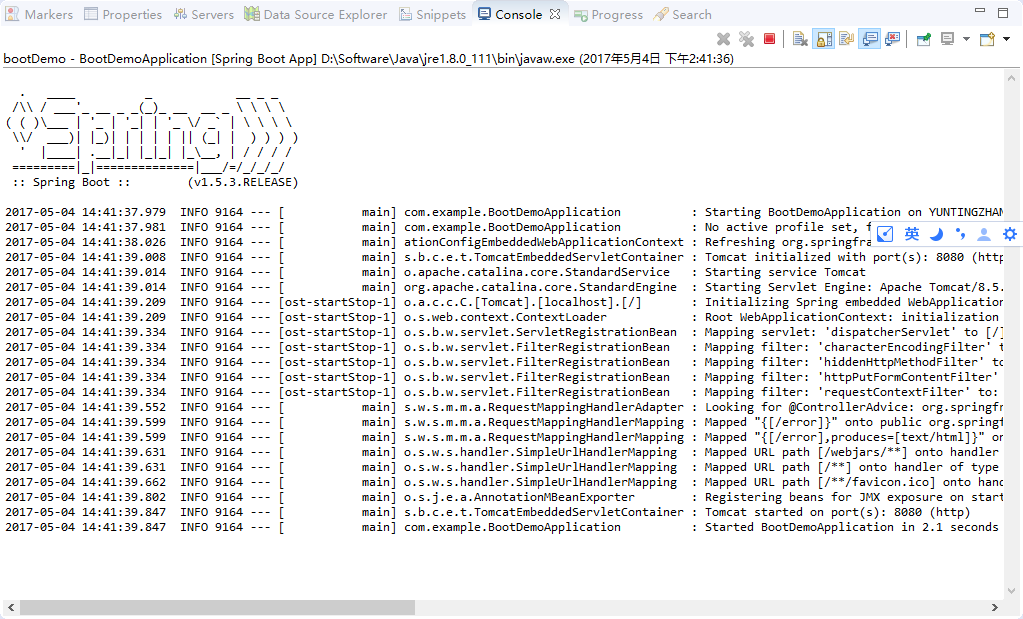
这样,一个Spring Boot 项目就搭建起来了。
4.可能会遇到的问题:
建立新项目后下载依赖的时候,可能会出现卡在那里不动的情况。这是因为国内连国外的镜像连不上造成的。可以修改maven中的镜像源,具体操作如下:
修改maven根目录下的conf文件夹中的setting.xml文件,内容如下:
|
|
改好之后,右击项目→【maven】→【update project】即可
如果还是不行的话,就去看看 用户名/.m2/目录下是否也存在一个settings.xml文件,这个配置文件的优先级是高于maven安装目录下的配置文件的。所以要把这个也改成阿里云的镜像。
|
|
5.参考链接:
Eclipse中创建新的Spring Boot项目
maven阿里云中央仓库
Maven2的配置文件settings.xml
6.Eclipse版本:eclipse-jee-neon-2-win32-x86_64.zip
kafka学习
kafka简介
首先,我们先来看一下 kafka 是用来干什么的
根据kafka官网的介绍,kafka主要用来做这么两件事儿:
- 搭建一个实时的流数据管道以支持系统间的实时数据通信。
- 搭建一个对流数据进行转换或响应的实时流应用。
为了实现这个目标,kafka 实现了以下三大关键特性
- 支持记录流(stream of records)的发布和订阅(有点儿像消息队列)。
- 允许你以一种高容错的手段存储记录流。
- 允许你实时地处理产生的记录。
初次之外,你可能还需要了解一些关于 kafka 其他的知识
首先,kafka 是运行在由一个或多个服务器组成的集群(cluster)上
kafka 集群将流(stream)按照不同的分类存储,每个分类叫做一个主题( topic)。
每一条记录(record)都包含一个键(key),一个值(value)和一个时间戳(timestamp)。
kafka原理
kafka 的四大 API
- Producer API :允许一个应用发布一个数据流到一个或多个 topic 上。
- Consumer API :允许一个应用订阅一个或多个 topic ,并对发送给它的数据进行处理。
- Streams API : 允许一个应用作为流处理器(stream processor)工作,即从某个或某些 topic 订阅,处理之后再发布到其他 topic 上。
- Connector API : 用于构建可重用的 producer 或 constmer 来把kafka 的 topic 连接到已有的系统上。比如,一个关系型数据库上的 connector 可以捕捉该数据库上某张表的内一个变化。
单台windows搭建redis集群
1.下载和安装必要的工具
1.1.下载安装redis for windows
下载地址:https://github.com/MSOpenTech/redis/releases
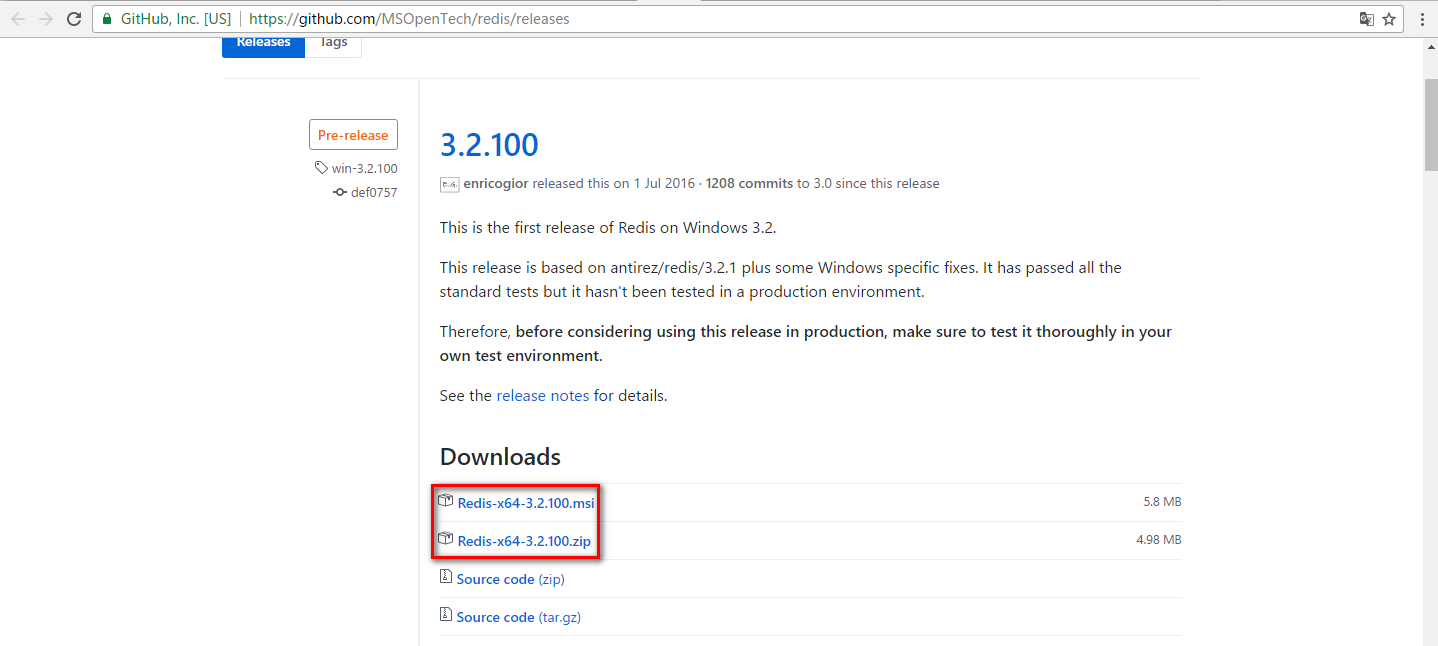
msi文件和zip文件,选一个下就行。msi文件是一个安装程序,有点类似于exe文件,双击就能运行。安装好之后跟用zip解压的结果是一样的。
1.2.下载安装ruby
下载地址:https://rubyinstaller.org/downloads/
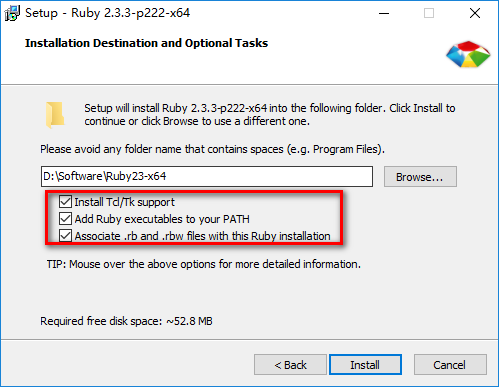
我下载安装的版本是Ruby2.3.3(x64)。安装的时候,记得把下面三个选项勾选上(如下图所示),这样就不用我们自己去配置环境变量了。
1.3.下载安装GEM:
下载地址:https://rubygems.org/pages/download
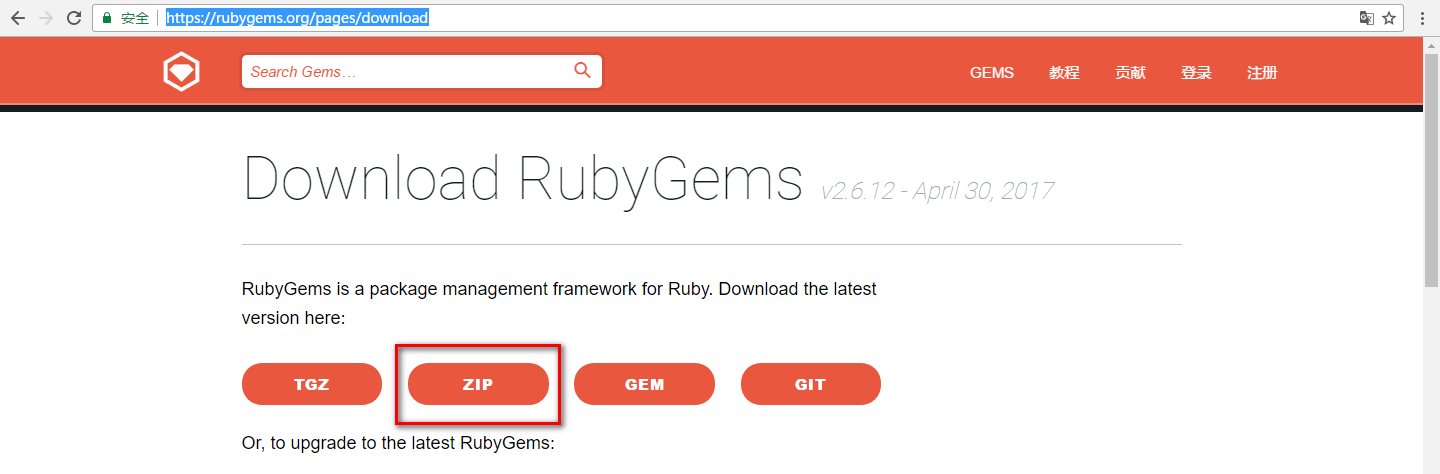
下载zip文件就行,解压到你喜欢的位置(我解压到了D:/software目录下)。
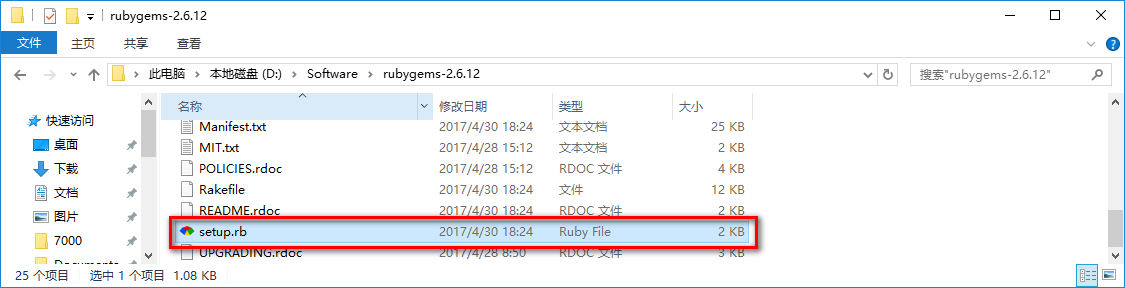
双击setup.rb,安装GEM。完成之后,把该文件夹的bin目录添加到系统变量中的path里面。
首先,复制该bin路径。
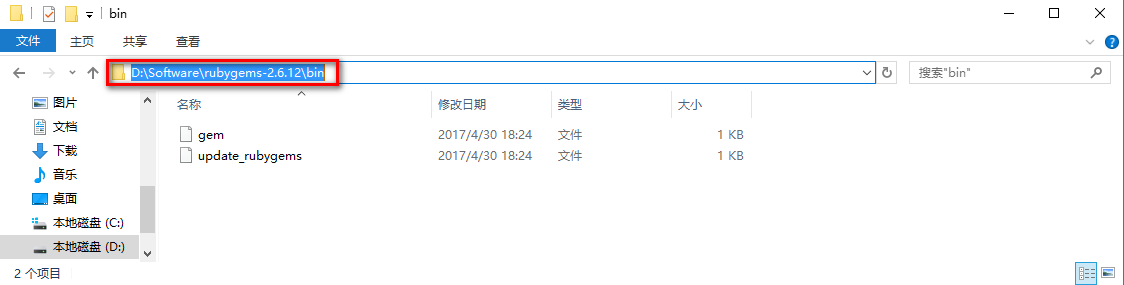
然后右键【此电脑】->【属性】
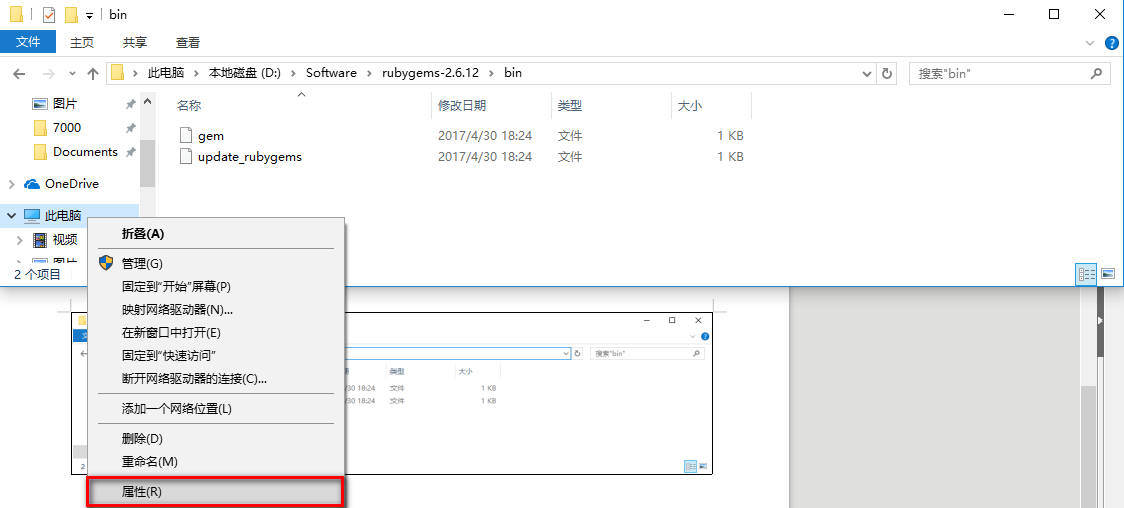
【高级系统设置】->【环境变量】->【系统变量】->【Path】->【编辑】
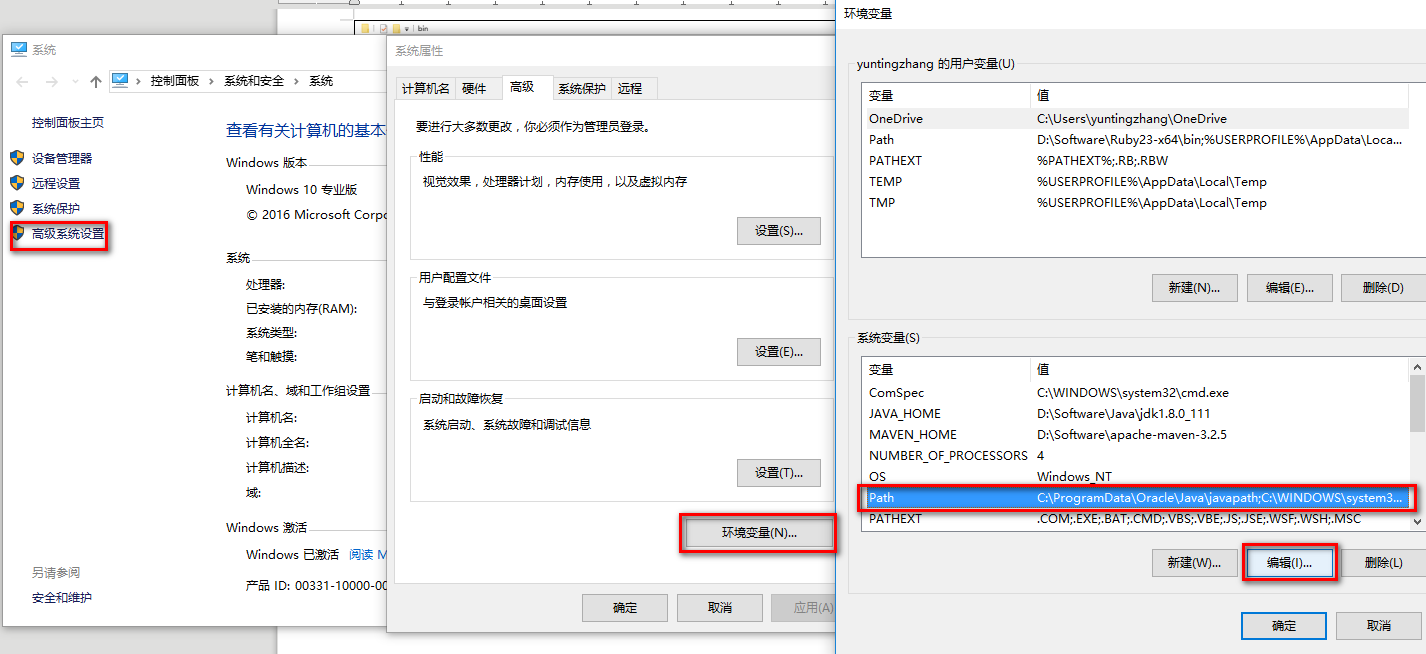
单击【新建】,把bin路径粘贴到方框中,然后点击【确定】即可。
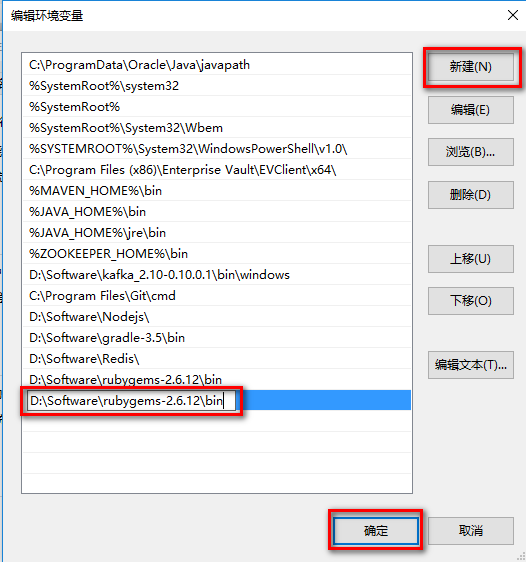
1.4.生成redis-trib.rb文件
新建一个文本文件,把它的名字改成redis-trib.rb。注意在改名之前先把隐藏的扩展名显示出来,否则会生成redis-trib.rb.txt文件。建好之后,访问:
https://raw.githubusercontent.com/antirez/redis/unstable/src/redis-trib.rb
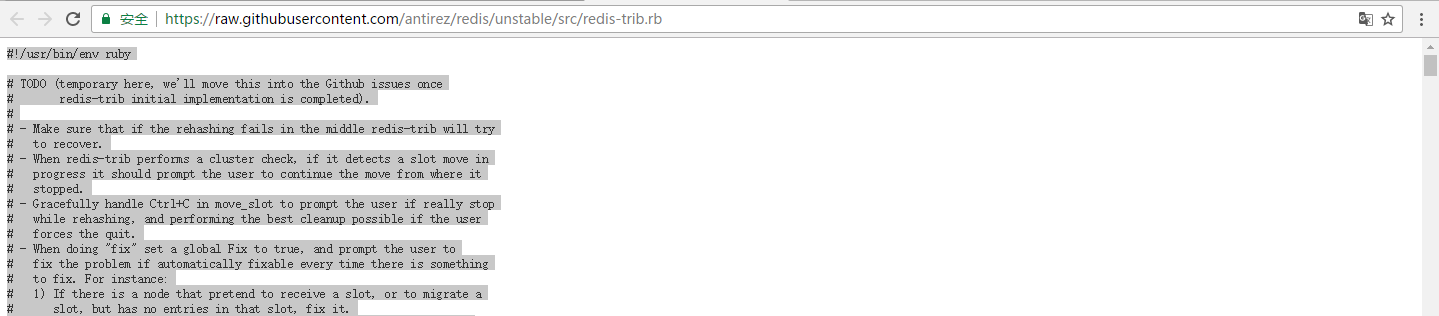
复制页面中的内容,粘贴到新建的redis-trib.rb文件中,保存。然后将此文件复制到redis的安装目录下(我的是D:\Software\Redis)。然后将这个目录也添加到系统变量的path中。
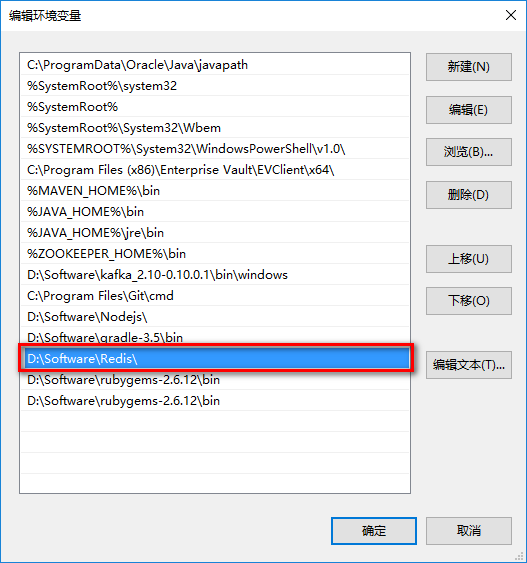
OK,这样准备工作就完成了。接下来我们要配置redis集群。
2.配置redis集群
2.1.创建相应目录:
在你喜欢的地方(我的是D:\WorkSpace)建立一个叫做redis的目录(注意,这个不是刚才安装redis的目录,而是一个你新建的目录,后文中如果没有特殊说明,redis目录都指这个新建的目录),里面创建6个子目录,分别叫7000,7001,7002,7003,7004,7005。
打开7000文件夹,建立一个redis.conf文件,将下面内容粘贴进去。
|
|
同理,在其他5个文件夹也各自创建一个redis.conf文件,将上面内容粘贴进去。不过要将prot和cluster-config-file中的7000改成对应的数字。如在7001文件夹中就改成7001。
2.2.Win+R输入cmd,回车,打开命令行。输入:gem install redis。
你显示的结果可能跟我稍微有些不一样,没关系,这是因为我刚才已经安装过了。
由于 GFW的问题, GEM 的源有时会不可用,如果你遇到了这个问题,可以使用淘宝的映像:
添加:gem sources -a https://ruby.taobao.org
查看已存在的源:gem sources -l
删除被墙的源:gem sources -r https://rubygems.org/
2.3.在D:\WorkSpace\redis目录下创建redis.bat文件
文件内容如下所示:12345678@echo offcd D:\WorkSpace\Redisstart Redis-Server ./7000/redis.confstart Redis-Server ./7001/redis.confstart Redis-Server ./7002/redis.confstart Redis-Server ./7003/redis.confstart Redis-Server ./7004/redis.confstart Redis-Server ./7005/redis.conf
双击redis.bat,弹出6个窗口,同时redis目录下会出现nodes-7000.conf 至 nodes-7005.conf 这几个文件。
2.4.在D:\WorkSpace\redis目录下新建cluster.bat文件
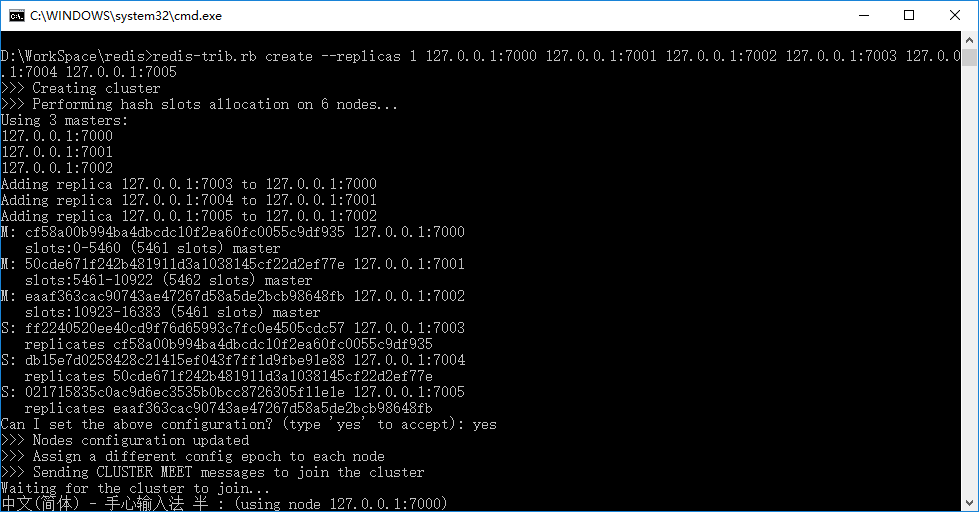
文件内容如下所示:12cd D:\WorkSpace\redisredis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
双击cluster.bat,在询问是否要接受配置时输入“yes”。
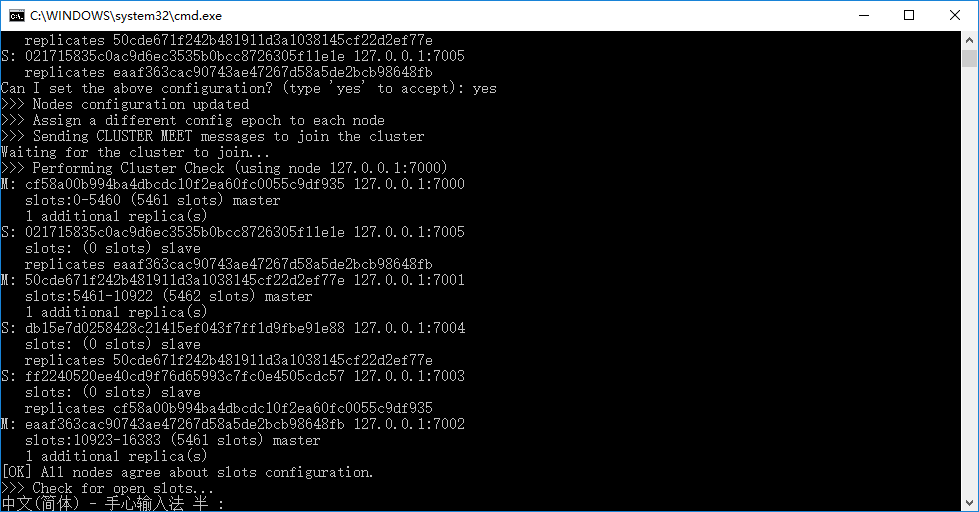
得到结果如下所示:
2.5.测试一下
打开cmd,输入:redis-cli.exe -c -p 7000
再打开一个cmd,输入redis-cli.exe -c -p 7001
它们连接了不同的实例,我们现在要测试以下它们的数据是否是同步的。
我们在7000的cmd窗口中输入: set test helloworld
在7001的cmd窗口中输入:get test
可以看到redis输出:”helloworld”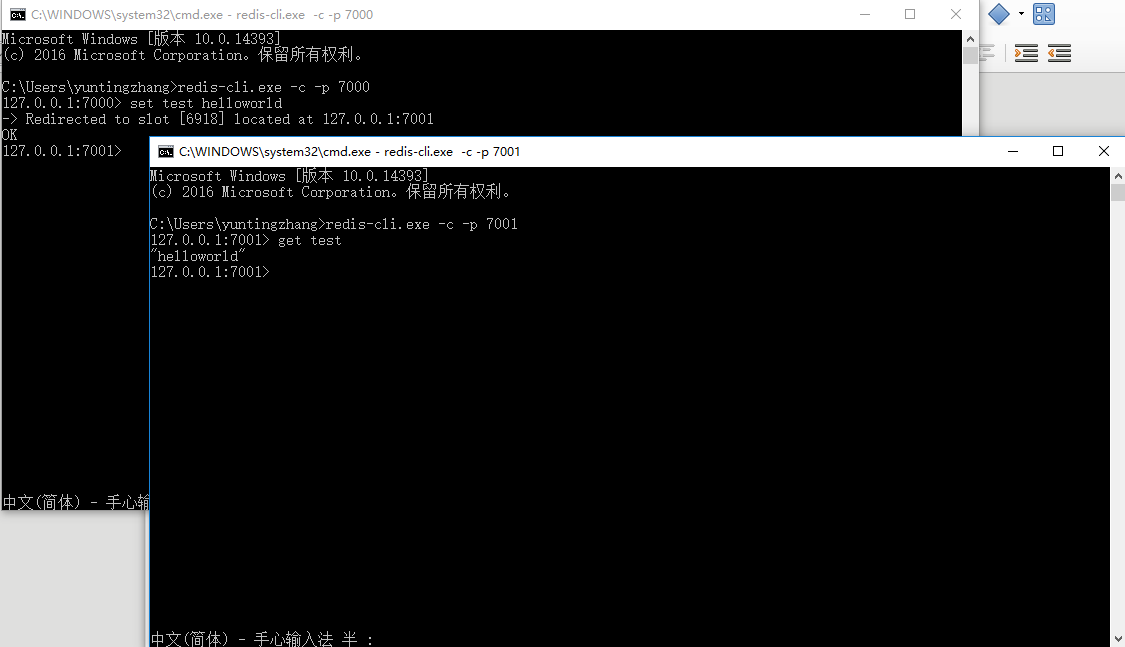
好,到这儿redis的集群就部署完成了。
3.参考链接:
Windows 部署 Redis 群集:
http://www.cnblogs.com/xling/p/5253063.html
Redis安装:
http://www.runoob.com/redis/redis-install.html
4.操作系统:Windows 10
后台开发知识点总结(六)大型网站架构
什么叫正向代理?什么叫反向代理?
正向代理是一种客户端主动使用的代理方式。它需要用户在客户端设置,对服务器透明。反向代理是一种服务器端使用的代理方式,它不需要用户在客户端进行设置,对客户端透明。譬如翻墙软件就是一种正向代理,而nginx是典型的反向代理,可以为服务器提供缓冲。
反向代理服务器与负载均衡服务器的区别?
反向代理服务器将静态资源存储到服务器上,以便用户能够更快地获得资源。负载均衡服务器之转发用户请求,不存储资源。
Redis的可排序集与集合的区别是什么?是怎么实现的?
可排序集在排序上拥有更高的效率(集合排序的时间复杂度为O),可排序集是借助跳表实现的。
什么是跳表?
跳表是一种可以用来替代树的数据结构,它的效率和AVL树不相上下。跳表由很多层构成,每一层都是一个有序链表。最下层包含了链表的所有元素,在上层出现的元素,下层还会出现。跳表使用上层来作为下层的索引,每个节点包含两个指针,一个指向后一个节点,一个指向下面的节点。跳表的空间复杂度期望为2n,其查找、插入和删除的时间复杂度均为O(log(n))。
跳表如何进行插入和删除?
跳表的插入比较复杂,首先要确定插入的元素所在的层数(用丢硬币的方法,丢到正面继续丢,丢到反面则停止。抛硬币的次数就是层数),如果层数超过当前层数,则在最上面添加新的层。跳表的删除比较简单,直接按照链表的方式删除即可。
介绍一下你所知道的缓存算法?
1.LRU 和 LFU:
LRU(按照上次使用时间排序)、LFU(按照使用频率排序)、LRU2(按照倒数第二次使用时间排序)。
2.LRU 升级版:
2Q(Double Queues,两个LRU队列,比例1:3,当对象被第二次访问,移入第二级队列),ARC(adaptive Replacement cache,LFU 的2Q版,两个队列,一个是最近被访问一次,另一个是最近被访问两次)。
3.基于 FIFO:
FIFO(先进先出)、Second Chance(带标记位的FIFO)、Clock(环形队列的Second Chance)。
4.基于时间:
绝对时间周期(相同寿命)、相对时间周期(相同时刻)、从上次访问开始算起的时间周期
5.移除最常用:
MRU(移除最近最多访问元素,因为找出最近最少被访问的时间复杂度高)。
Redis的优势在于哪?
首先,Redis支持多种数据类型(字符串、列表、哈希、集合、有序集合)以及它们的原子性操作。另外,Redis支持数据的持久化和 Master-Slave 模式的数据备份。
负载均衡服务器的三大特性?
负载均衡算法(轮询、最小连接数、最快响应时间、比率、优先权、哈希、基于策略(自定义)、基于数据包)、健康检查(Ping、TCP、UDP、HTTP、FTP、DNS等,七层网络中的三到七层)和会话保持(同一用户访问到相同服务器)。
线程的状态有几种?
新建、就绪、运行、阻塞、死亡。
终止线程有几种方式?
通过标志位控制退出(while(volatileexit))、通过stop的方法来终止线程(thread.stop())、通过中断的方法终止进程(thread.interuped())。
什么叫缓存穿透?怎么预防?
缓存穿透指的是访问一个不存在的数据,由于这样缓存不可能命中,缓存就会去数据库中直接读这个数据,给数据库造成压力。预防的方式是使用一个布隆过滤器,即把数据库中所有可能的值 hash 到一个足够大的 bItmap 上去,请求到达时先用过滤器检测是否由该数据,如果有再去缓存中读取。
不同缓存系统中的缓存算法分别是怎样的?
Redis2.6/ Encache/ Hazelcast:随机找3条/ 8条/ 25条,删去其中空闲时间最长的数据。
Redis3.0:随机找五条,插入一个长度为16按空闲排序的队列里,每次删去最老的元素。
MemCached/ Guava Cache:纯粹的LRU,维持一个双向链表,插入到链表头,删除时把前后两个元素连接起来。
不同缓存系统对于过期键是怎么删除的?
所有缓存系统对于过期键都采用惰性删除的方式,也就是说,并不是数据一过期就删除(因为执行检查的线程耗费cpu),而是只有元素被访问时,才会检查它是否超时了。为了防止不被访问的数据永远不被清理,不同缓存系统提供了不同的策略去清理这样的数据:
Redis:每100ms抽取20条进行检查。如果有超过1/4过期,那么立即进行下一轮检查。
MemCached:有一个检查线程从双链表队尾往前检查,每隔一段时间(默认100ms)执行一次。
Guava Cache:由于在这个系统中,同一个Cache里所有数据同时过期,因此只需要从队尾向前检查直到不过期为止。每次写入数据都会调用此方法。
Ehcache:只有惰性检查,没有主动过期。
设计缓存算法需要考虑的因素有哪些?
成本:如果对象获取成本不同,难以获取的元素需要尽可能的保存。
容量:先清除大对象,这样就可以把更多的小对象换进内存。
时间:如果系统缓存着过期时间,那么对过期的数据进行清理。
Redis 和 Memcached 分别是怎么实现的?
http://blog.csdn.net/u014743697/article/details/53442512
Select、poll 和 epoll 的区别?
http://www.cnblogs.com/Anker/p/3265058.html
数据库分区与分库分表(Sharding)的区别是什么?
http://blog.csdn.net/heirenheiren/article/details/7896546
数据库分库分表(Sharding)的步骤是什么?
http://blog.csdn.net/bluishglc/article/details/6161475
多级缓存是怎么实现的?
后台开发知识点总结(五)设计模式
什么是代理模式?
代理模式是java中常用的设计模式,它的特点是代理类与委托类实现同样的接口。代理类并不真正地实现服务,而是通过调用委托类对象的方法,提供特定的分服务。
什么是动态代理?它的优点是什么?
按照代理的创建时期,代理可分为两种。程序运行前就已经创建好的叫做静态代理,程序运行时利用反射机制动态生成的叫做动态代理。动态代理的优点是只需要一个代理类就能实现全部的代理功能。
如何实现一个动态代理?
实现一个动态代理有两种方法,一种是使用 JDK 实现动态代理,另一种是使用 Cglib 实现动态代理。
前者的代理类需要实现 InvocationHandler 接口(该接口要实现一个 Invoke() 方法),并用在Bind 方法中调用 Proxy 的 NewProxyInstance 方法创建代理实例。在创建代理实例的过程中,需要绑定委托类实现的(提供相关服务的)接口。如果委托类没有实现接口,那么这种方法不能使用。
后者是生成一个代理类的子类,需要实现 MethodInterceptor 接口(该接口要实现一个 intercept() 方法),并在 getNewInstance() 中创建一个实例,然后把其父类设定为委托类,并返回该实例。由于这种方法是基于继承的,因为 final 类不能使用。
参考链接:http://www.cnblogs.com/jqyp/archive/2010/08/20/1805041.html
如何利用动态代理实现 Spring AOP?
后台开发知识点总结(四)数据库
位图索引
所谓位图索引,就是用一个二进制向量表示一张表中所有数据的某个属性。如一张User表中所有人的性别,或者是User表中所有人的已婚状况。像这种只有两个(或几个)固定值的属性,即使使用B树索引,还是需要取出一半的数据,因此并不能显著地提升效率。
使用位图索引的好处是,可以通过对两个索引进行and操作来快速地找到同时满足两个属性的样本。如要找出User中所有的未婚男性,只需要把性别和已婚状况两个位图索引做and操作,就能快速地得到结果。
位图索引适用于那种只有几个固定值而且不会频繁更新的列。
MySQL不支持这种索引。
MySQL数据库引擎有几种?
ISAM、MYISAM、HEAP、INNODB、BERKELEYDB。
MYISAM 和 INNODB 有什么区别?分别适用于什么情况?
INNODB 支持事务、外键和行级锁,MYISAM 不支持。不过,INNODB 不支持 FULLTEXT 索引,也不保存表具体的行数。
INNODB 比较适合更新比较频繁,或者是要求事务的场景。而 MYISAM 比较适合查询频繁、不要求事务和频繁使用count 的场景。
INNODB 的行级锁什么时候有效?什么时候无效?
只有在 WHERE 判断中是主键的时候有效,其他情况同样会锁全表。
INNODB 和 MYISAM 的索引是怎么实现的?
INNODB 和 MYISAM 的索引都是基于 B+ 树实现的。两者的区别在于,MYISAM 主键索引和辅助索引记录的都是每条数据的地址。而 INNODB 主键索引记录的就是数据本身,辅助索引记录的是主键。因此 INNODB 使用辅助索引需要对主键进行二次索引。所以, 使用 INNODB 的时候应尽量把主键定义得小一些。
B+树、B-树、B*树有什么区别?
B+树与B-树的区别在于:B-树的关键字分布在整棵树中,且一个关键字只出现一次;而B+树中所有关键字都在叶子节点出现,且可以出现多次。另外,B+树为所有叶子节点增加了链指针,且要求非叶子节点子树指针与关键字个数相同。B*树为所有非根非叶子节点也添加了指向兄弟的指针。
INNODB 和 MYISAM 的缓存有什么异同?
INNODB 和 MYISAM 的缓存都是基于LRU算法实现的。区别在于,MYISAM 的缓存 Key Cache 只缓存索引,而 INNODB 的缓存 buffer pool 不仅缓存索引,还缓存数据。INNODB 通过存储日志把内存数据同步到磁盘(因为存储日志是连续存储,速度快;读写数据是随机读写,速度慢)。如果条件允许,可以开辟尽量大的空间作为 buffer pool,这样系统的性能更接近内存数据库。
数据库的锁有几种?
三种。共享锁(S锁,只进行读操作时使用的锁,数据上存在共享锁时不得被更改,以单独去完成马上释放共享锁)、排他锁(X锁,可以防止资源的并发访问,其他事务既不能更改也不能读取上面有排他锁的资源)、更新锁(U锁,一次只有一个事务可以获得某资源的更新锁。如果事务对资源进行更新,则转换为排他锁。若仅进行读取则转换为共享锁。)。
更新锁和排他锁的区别是什么?
更新锁的存在主要是为了防止事务之间发生死锁。事务在修改数据时,首先会获取该资源的共享锁,然后在更改时转换为排他锁。如果两个事务都获取了共享锁而等待另一个事务释放共享锁,那么就会发生死锁。由于更新锁一次只可以被一个事务获取,因此避免了这种死锁的发生。
MySQL数据库索引有几种?
四种。分别是FULLTEXT索引、HASH索引、BTREE索引、RTREE索引。
什么叫FULLTEXT索引?
FULLTEXT索引主要是为了解决WHERE name LIKE “%word%” 操作而产生的。如果没有FULLTEXT索引,那么就要遍历全表。MySQL中,只有MYISAM支持这种索引。
FULLTXET索引依靠词典(所有的单词,所有的非字母和数字都会被认为是单词的分隔符)和倒排表(一个链表,记录了每个单词对应的所有包含该单词的记录(按照某种顺序)组成的链表)实现。查找同时包含两个单词的记录时,合并其对应的链表即可。
HASH索引和BTREE索引有什么区别?
HSAH索引不能使用范围查询,也不能避免排序操作。另外,HSAH索引不能利用部分索引键查询。
简单介绍一下R树?
R树是B树在高维空间的扩展。简单来说,B树每个节点描述的是一个线段,而R树所描述的是一个矩形或立方体(当然,也可能是更高维)。父节点表示的矩形应当能够包括所有子节点所包括的矩形。
这种数据结构主要用来搜索多维空间,比如一个人附近的餐厅。如果没有R树,就需要对所有餐厅的横纵坐标进行比较。而有了R树之后。只需要找到对应的节点就可以了。